0.目录
-
什么是拷贝
-
拷贝需要考虑的几个问题
-
C++中的拷贝概念及操作
-
现代C++11 中的移动语义和右值引用
-
案例
1.什么是拷贝?
先说是什么,再说为什么。
什么是拷贝?在C++中,拷贝(Copy)是指创建一个与现有对象状态完全相同的新对象的过程。英文概念为:
Copy (in C++): The process in which a new object is created that has an identical state to an existing object.
很抽象,进一步问,主从对象的关系是怎样的?
在现代C++中,当我们讨论对象的主本和副本之间的关系时,我们通常指的是原始对象(或称源对象)与通过拷贝构造函数或赋值运算符创建的新对象(即副本)之间的关联。
状态的复制过程: 当一个对象被拷贝时,其状态包括所有数据成员(包括基本类型成员、引用、指针以及类类型的成员等)。浅拷贝操作会逐个复制这些数据成员的值,而对于指针或引用成员,只复制指针或引用本身,而不复制它们所指向的数据。这意味着原始对象和副本可能共享资源。
深拷贝则不仅复制数据成员的值,还会确保动态分配的资源(如内存块、文件句柄等)也被正确地复制,这样原始对象和副本各自拥有独立的资源,对副本的操作不会影响到原始对象的状态。
主从关系:
- 主本:原始对象,是被拷贝的对象。
- 副本:新创建的对象,它的状态来源于主本对象。
在函数调用过程中,如果传入参数采用传值方式,函数接收的是主本的一个副本。此时,函数内部对副本的任何修改都不会直接影响到主本。但如果只是进行了浅拷贝,并且涉及到共享资源,则可能会间接影响主本对象的生命周期或其他状态。
p300 讲的:拷贝的默认含义就是拷贝所有的数据成员。
2.为什么要拷贝?及 demo
为什么这个问题很难回答,简单来说,知道一个即可:拷贝对象主要是为了维护数据的一致性和完整性,以及实现不同代码模块间数据的有效隔离和管理。 以下会用一个很实际的例子,来感受拷贝存在的意义,来说明为什么:
2.1 学生类
拷贝对象在程序设计中的一个简单的需求是保留原始数据,同时对副本进行修改,而不影响原始数据。这种情况通常发生在函数参数传递或者数据备份的过程中。 举个简单的例子,假设我们有一个表示学生的类 Student,其中包含姓名和年龄两个成员变量。现在我们希望编写一个函数,用于修改学生的年龄,但又不想修改原始的学生对象,而是创建一个副本进行修改。
#include <iostream>
#include <string>
class Student {
private:
std::string name;
int age;
public:
Student(const std::string& n, int a) : name(n), age(a) {}
void setName(const std::string& n) {
name = n;
}
void setAge(int a) {
age = a;
}
void print() {
std::cout << "Name: " << name << ", Age: " << age << std::endl;
}
};
// 函数用于修改学生的年龄,但不影响原始对象
void changeAge(Student s, int newAge) {
s.setAge(newAge);
std::cout << "Modified student information inside the function: ";
s.print();
}
int main() {
Student original("Alice", 20);
std::cout << "Original student information: ";
original.print();
changeAge(original, 25);
std::cout << "Original student information after function call: ";
original.print();
return 0;
}

这种按值传递的方式,会创建 对象的一个新副本 ,因此修改副本的属性不会影响原始对象。
2.2数据备份
看看demo:
class Data {
private:
std::string content;
public:
Data(const std::string& c) : content(c) {} // & reference, c是const std::string
// 拷贝构造函数,用于创建对象的副本
Data(const Data& other) : content(other.content) {}
void print() const {
std::cout << "Content: " << content << std::endl;
}
void setContent(const std::string& c) {
content = c;
}
};3.有关拷贝的概念
3.1拷贝构造函数
拷贝构造函数的参数通常是一个常引用类型的对象引用,参数名通常是 other 或者 source,表示需要被复制的原始对象。
class MyClass {
public:
// 拷贝构造函数
MyClass(const MyClass& other) {
// 进行成员变量的初始化,通常是通过将其他对象的成员变量赋值给当前对象
// 可以使用成员初始化列表或者在函数体内进行初始化
}
};
这里参数的设置是一个编程习惯 idioms ,other 或者 source 就是指代原始对象(或者说上面的主本)。
下面这个demo,有一个拷贝赋值概念,其实就是初始化:
#include <iostream>
class MyClass {
private:
int value;
public:
// 构造函数
MyClass(int v) : value(v) {}
// 拷贝构造函数
MyClass(const MyClass& other) : value(other.value) {
std::cout << "Copy constructor called" << std::endl;
}
// 打印成员变量的值
void print() const {
std::cout << "Value: " << value << std::endl;
}
};
int main() {
// 创建原始对象
MyClass original(10);
std::cout << "Original object:" << std::endl;
original.print();
// 复制对象
// 拷贝赋值完成初始化
MyClass copy = original; // 调用拷贝构造函数
std::cout << "\nCopied object:" << std::endl;
copy.print();
return 0;
}

3.2浅拷贝
引用(reference)-> shallow
如果希望函数能够修改原始对象的属性,可以使用引用或指针作为函数参数传递,这样函数将直接操作原始对象。
class ShallowCopyDemo {
private:
char *name; // 字符串指针成员变量
bool shouldDelete; // 是否应该删除指针(一个标志)
public:
// 构造函数,初始化 name 指针并复制字符串内容
// 这里为什么不写成 ShallowCopyDemo(const char* n) : name(n) {} ?
ShallowCopyDemo(const char *n) {
// 分配堆区内存并复制字符串内容
name = new char[strlen(n) + 1]; // 字符串结尾的空字符
// char* strcpy(char* dest, const char* src); dest是目标,src是源
strcpy(name, n);
shouldDelete = true;
}
// 拷贝构造函数,执行浅拷贝
ShallowCopyDemo(const ShallowCopyDemo &other) { // &这里是引用 reference
// 直接复制指针,而不是复制字符串内容
name = other.name;
shouldDelete = false;
}
// 打印名称
void printName() const { std::cout << "Name: " << name << std::endl; }
// 析构函数,释放动态分配的内存
// ~ShallowCopyDemo() {
// if (name != nullptr) {
// delete[] name;
// name = nullptr;
// }
// }
// ~ShallowCopyDemo() { delete[] name; }
~ShallowCopyDemo() {
if (shouldDelete) {
delete[] name;
}
}
};
之类有一点点问题是,我的析构函数还是写成了:
~ShallowCopyDemo() { delete[] name; }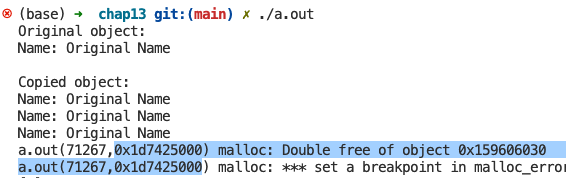
浅拷贝的demo操作起来真的麻烦,还要设置标志flag之类的,总之是编译通过了。
改造后的析构函数,我们将之前设置的标志flag用到了:
~ShallowCopyDemo() {
if (shouldDelete) {
delete[] name;
}
}这时,析构函数就能判断,我到底要不要delete两次。
private:
char *name; // 字符串指针成员变量
bool shouldDelete; // 是否应该删除指针(一个标志)这里看看标志flag是干什么的? 这里的 [shouldDelete](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-sandbox/workbench/workbench.html) 标志用于指示是否应该在析构函数中删除 [name](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-sandbox/workbench/workbench.html) 指向的内存。在构造函数中,我们设置 [shouldDelete](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-sandbox/workbench/workbench.html) 为 true,因为我们在构造函数中使用 new 分配了内存。这意味着当对象被销毁时,我们需要在析构函数中使用 delete[] 来释放这块内存。
这里可以看到,两块内存区域是一样的。这就实现了 reference,下面再用可视化来深度体验下:
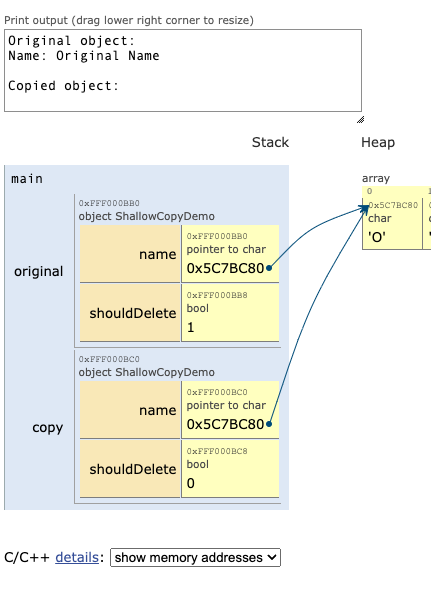
上图! 然而,在拷贝构造函数中,我们进行了浅拷贝,即只复制了 [name](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-sandbox/workbench/workbench.html) 指针,而没有复制 [name](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-sandbox/workbench/workbench.html) 指向的内存。这意味着原始对象和拷贝的对象的 [name](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-sandbox/workbench/workbench.html) 成员都指向同一块内存。
如果我们在两个对象的析构函数中都删除 [name](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-sandbox/workbench/workbench.html),那么就会尝试删除同一块内存两次,这是一种未定义行为。为了避免这种问题,我们在拷贝构造函数中设置 [shouldDelete](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-sandbox/workbench/workbench.html) 为 false,这样,拷贝的对象在被销毁时就不会删除 [name](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-sandbox/workbench/workbench.html) 指向的内存。
下面是pythontutor的gif:
3.3深拷贝
值(value)-> deep
按值传递的方式,会创建对象的一个新副本,因此修改副本的属性不会影响原始对象。
上面都是深拷贝的例子,可以看到内存是两块不同的区域。
4.移动语义与&&
概念:C++11中引入的概念,它允许在资源转移时避免不必要的数据复制,提高程序的性能和效率。通过移动语义,可以将资源的所有权从一个对象转移到另一个对象,而不是通过传统的拷贝操作。
笔记:这样理解移动语义move,就是这是一个“思路”,最终的使用要借助&&。
右值引用(rvalue reference)
右值引用:&& 。 与左值引用 & 相比,右值引用的主要区别在于它们能够绑定到临时对象和将要销毁的对象。左值引用主要用于绑定到具名对象,而右值引用主要用于绑定到临时对象。
然后,什么叫做临时对象和将要销毁的对象? 临时对象就是,通常用于 表达式计算的中间结果 或者作为函数的返回值。一旦它们的作用域结束或者表达式求值完成,临时对象就会被销毁。
为什么我们需要将左值对象转换为右值引用 && 呢?主要是因为右值引用可以触发移动语义,避免不必要的数据复制,从而提高程序的性能和效率。有时候,我们可能有一个具有名称的对象,但是我们希望它的资源能够被另一个对象所管理,而不是进行复制。这时候,我们就需要将这个左值对象转换为右值引用,并将其传递给需要移动资源的函数或者赋值给另一个对象,以便触发移动语义。
笔记:右值引用 && 为了触发移动语义。
调试了半天,这里用这个例子来解释吧,非常易懂:
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec1 = {1, 2, 3, 4, 5};
std::vector<int> vec2 = std::move(vec1); // 使用 std::move 将 vec1 转移到 vec2
std::cout << "Size of vec1: " << vec1.size() << std::endl; // 输出:0
std::cout << "Size of vec2: " << vec2.size() << std::endl; // 输出:5
return 0;
}
为什么 vec1 是 0 ?
在这段代码中,我们使用了 std::move 将 vec1 中的内容移动到了 vec2 中。这意味着在执行完 std::move(vec1) 后,vec1 不再持有原有的数据,它的内部状态变为空,即不再包含任何元素。
在这个示例中,std::move(vec1) 将 vec1 中的数据转移到了 vec2 中,vec1 的大小变为 0。通过使用 std::move,我们成功地实现了资源的转移,而不是进行数据的复制。
笔记:这个转移只是内存所有权的转移,也不是真正的转移,总之就是告诉编译器,好了这里理解成 rvalue 就行。
反正,这一块理解到这里就行。 第4节部分,确实花费我不少时间,可以说是走弯路了。 这个东西不用费劲地去理解,就是C++11给了个新东西是移动语义,就是把A对内存X的所有权转移给B,仅此而已,然后要用到&&来做这件事还有std::move 。这件事,最简单的就是看成是房屋买卖或者租借,具体往进带入就行。




暂无评论