这里主要是讲述C语言和汇编语言之间的接口。
1. C语言与汇编接口
C语言和汇编语言之间的接口通常通过函数调用来实现。有3种调用方式:
-
内联汇编的方式 inline asm
-
使用
extern来C语言调用汇编 -
汇编调C
前两个可以进行demo演示,最后一个汇编调C,不演示了,太耗精力了,道理是一样的。
1.2 内联汇编
测试平台为:Darwin Kernel ,arm64
#include <stdio.h>
void swap_asm(int* a, int* b)
{
// inline assembly syntax: __asm__ (assembly code : output operands : input operands : clobbered registers)
// x86 architecture uses 8086 uses Intel syntax, but is just different in syntax.
__asm__(
"mov x0, %0\n" // 将参数 a 的值存储到 x0 寄存器中
"mov x1, %1\n" // 将参数 b 的值存储到 x1 寄存器中
"mov %0, x1\n" // 将 x1 寄存器中的值存储到 a 中
"mov %1, x0\n" // 将 x0 寄存器中的值存储到 b 中
: "+r"(*a), "+r"(*b) // 输入输出约束
);
}
int main()
{
int a, b;
printf("Enter two numbers: ");
scanf("%d %d", &a, &b);
// swap_asm(&a, &b);
printf("Swapped numbers: %d %d\n", a, b);
return 0;
}
这句话进行了注释,可以看到变量交换并没有完成。
// swap_asm(&a, &b);
具体演示请看视频操作。
《微机原理与接口技术》p46
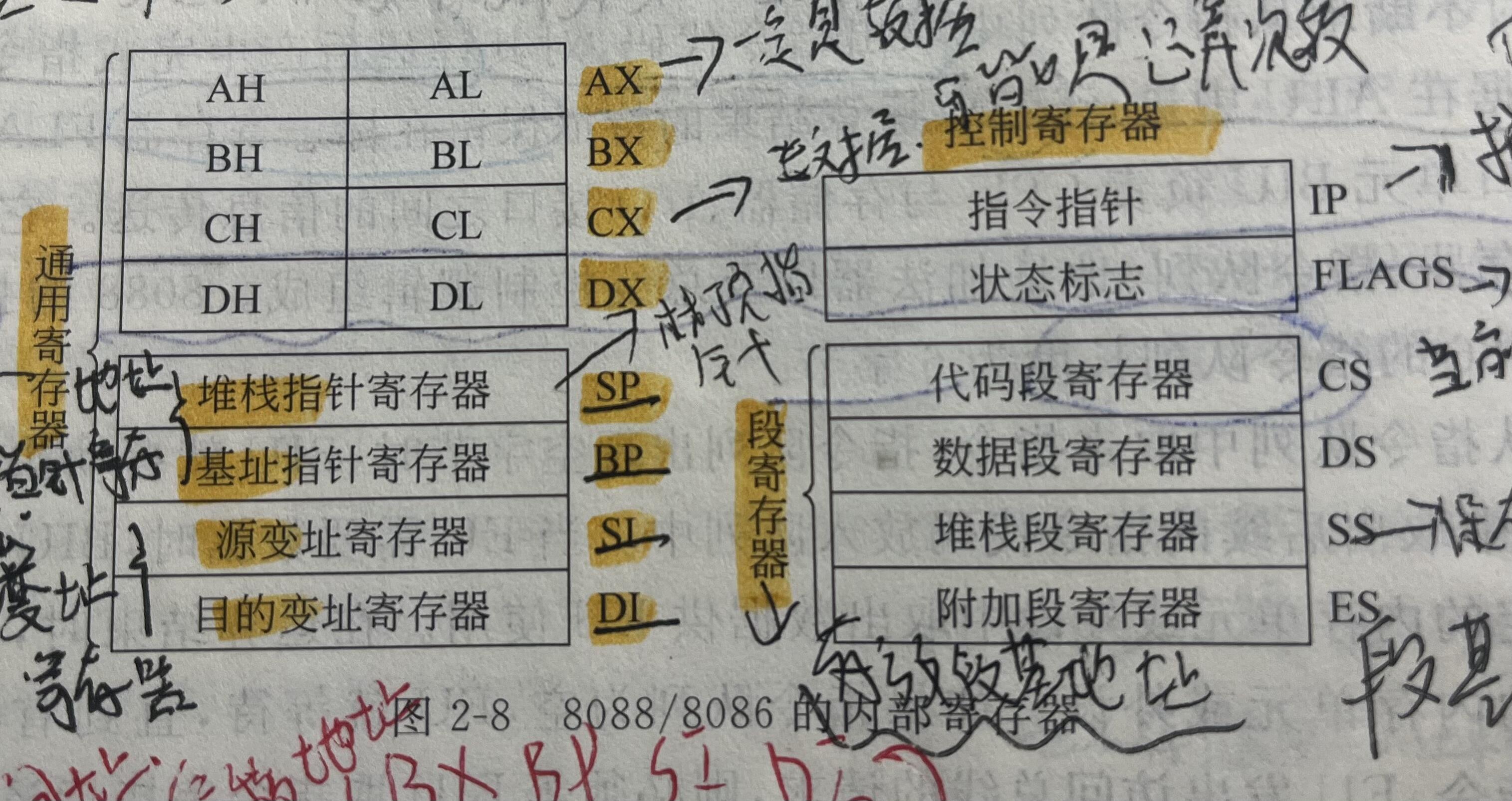
《C指针编程之道》 p215
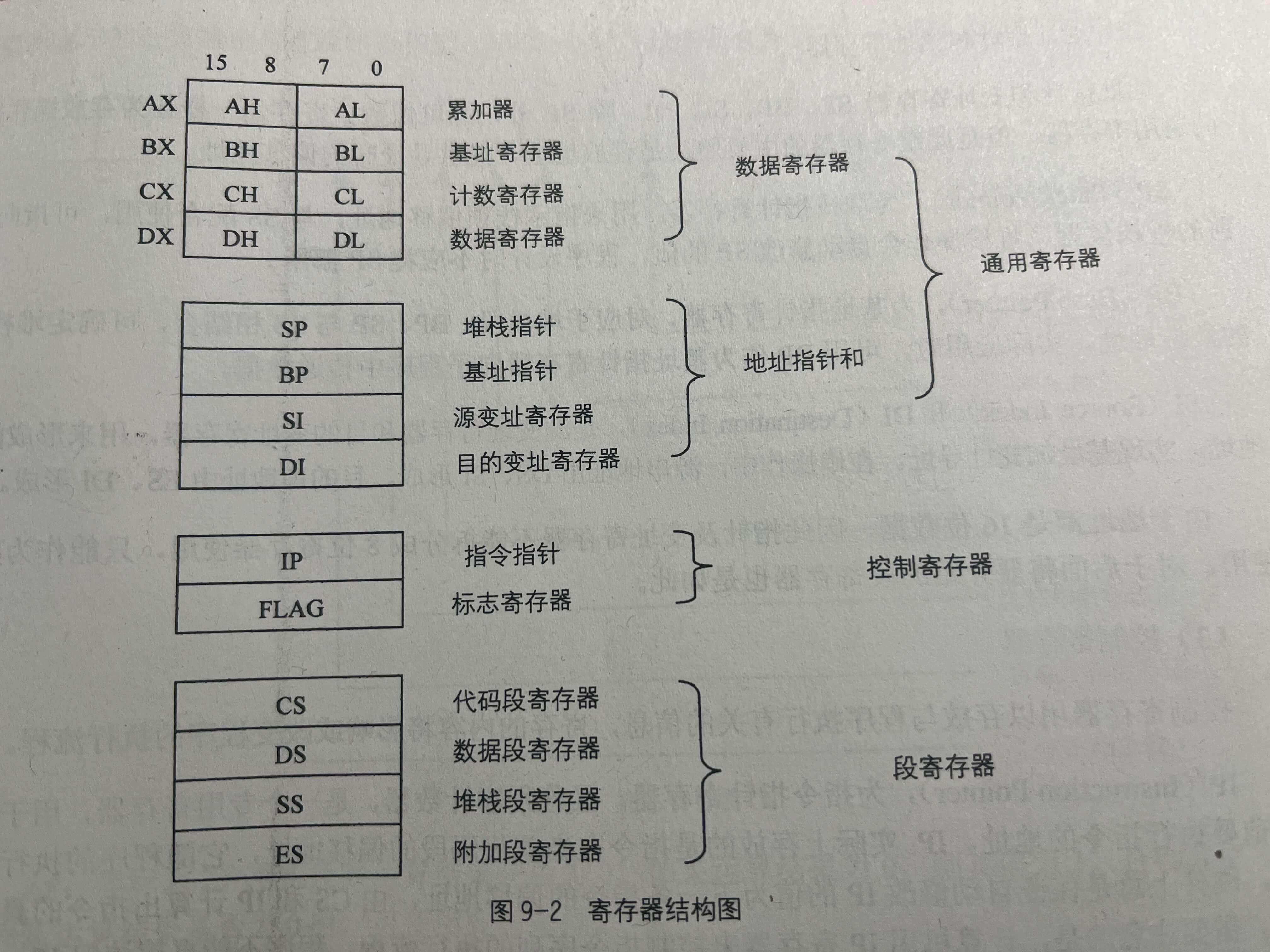
由此我们可以知道,8086CPU有14个16位的通用寄存器。
然后再来看看A64 和 8086 有什么区别:
ARM64架构中的通用寄存器的命名规则如下:
-
w0到w30:32位通用寄存器,用于存储32位数据。 -
x0到x30:64位通用寄存器,用于存储64位数据。 -
sp:栈指针寄存器,用于指向当前栈顶。 -
lr:链接寄存器,用于存储函数调用的返回地址。 -
pc:程序计数器,用于存储当前正在执行的指令的地址。
w0 通常用于存储临时数据、函数参数传递或者函数返回值等。
用表格更加清晰:
| 寄存器 | 类型 | 用途 |
| ------ | ---- | ---------------------------------------- |
| w0 | 32位 | 存储32位临时数据、函数参数传递、返回值等 |
| w1 | 32位 | 存储32位临时数据、函数参数传递等 |
| … | … | … |
| w30 | 32位 | 存储32位临时数据、函数参数传递等 |
| x0 | 64位 | 存储64位临时数据、函数参数传递、返回值等 |
| x1 | 64位 | 存储64位临时数据、函数参数传递等 |
| … | … | … |
| x30 | 64位 | 存储64位临时数据、函数参数传递等 |
| sp | 64位 | 栈指针寄存器,指向当前栈顶 |
| lr | 64位 | 链接寄存器,存储函数调用的返回地址 |
| pc | 64位 | 程序计数器,存储当前正在执行的指令的地址 |
发现什么没有? 8086 和 A64相比,没有pc ,后面会讲到。
还有一点就是编译的时候很烦,会有很多警告,建议使用参数w屏蔽
gcc -w inline-asm.c
1.2 extern
先讲一下A64汇编基础
# main.s
# Assemble with: as -o main.o main.s
# ; is a comment
# .section is a directive that tells the assembler to put the following code in the __TEXT,__text section
# Directives are instructions to the assembler that are not part of the instruction set 不执行只告知
# Mach-O 文件格式有段Segment、节Section、页Page ` .p2align 2 ; ` 指令对齐,就这么写
.section __TEXT,__text
.globl _main ; 一样的,告知一下OK这个程序是有入口main的
# .p2align 2 ;
_main:
mov w0, #0 ; w0是通用寄存器,这里是把w0寄存器的值设为0。#是为了区别立即数和寄存器
ret
下面看这段汇编代码:
.global _swap_asm
.section __DATA,__data
var1: .byte 10
var2: .byte 20
.section __TEXT,__text
_swap_asm:
// mov 报错
#mov x2, var1 // 将 var1 的地址存储到 x2 寄存器中
#mov x3, var2 // 将 var2 的地址存储到 x3 寄存器中
ldrb w0, [x2] // 将 var1 的值加载到 w0 寄存器中
ldrb w1, [x3] // 将 var2 的值加载到 w1 寄存器中
strb w0, [x3] // 将 w0 寄存器中的值存储到 var2 中
strb w1, [x2] // 将 w1 寄存器中的值存储到 var1 中
ret // 返回
ldbr 和 strb 就是用于装载XXX到内存的东西,大概知道就行。
然后,看看 extern 关键字的用法:
// extern syntax is : extern return_type function_name(parameters);
extern void swap_asm(int *a, int *b);
然后看视频演示,
最后需要注意的是,直接使用链接器 ld 会报错,就是找不到。嗯,使用如下指令就可以:
ld swap.o swap-a64.o -lSystem -L $(xcrun --show-sdk-path -sdk macosx)/usr/lib -o prog
具体为什么,不要问。然后程序在运行的时候,还是出现了错误,这一点我还没debug好。主要是演示,C和汇编的混编可以做,具体汇编的问题先忽略。
https://gist.github.com/Evian-Zhang/19c63a1f1a1a58bdd4b86836a8b3ba0f
1.3 汇编调C
略
这里要提到一个东西,函数栈帧(Function Stack Frame). 可以看无边际的画
记住:汇编调用C是使用call语句进行外部函数的调用,还有就是调用结束就是要立即去平衡堆栈,就是修改栈顶。
伪码演示:
// 省略一些外部说明什么之类的...
// main 函数里的 func
func proc
mov xx,xx
push xx,xx
call swap // swap()
add sp,2 // notice!
ret
func endp
end
为什么要修改栈顶? 就是上面提到的函数栈帧(Function Stack Frame),修改就是为了释放,使得堆栈恢复到调用前的状态。
1.4 一些个题外话
-
远近指针
-
内存模型
p223 《C指针编程之道》
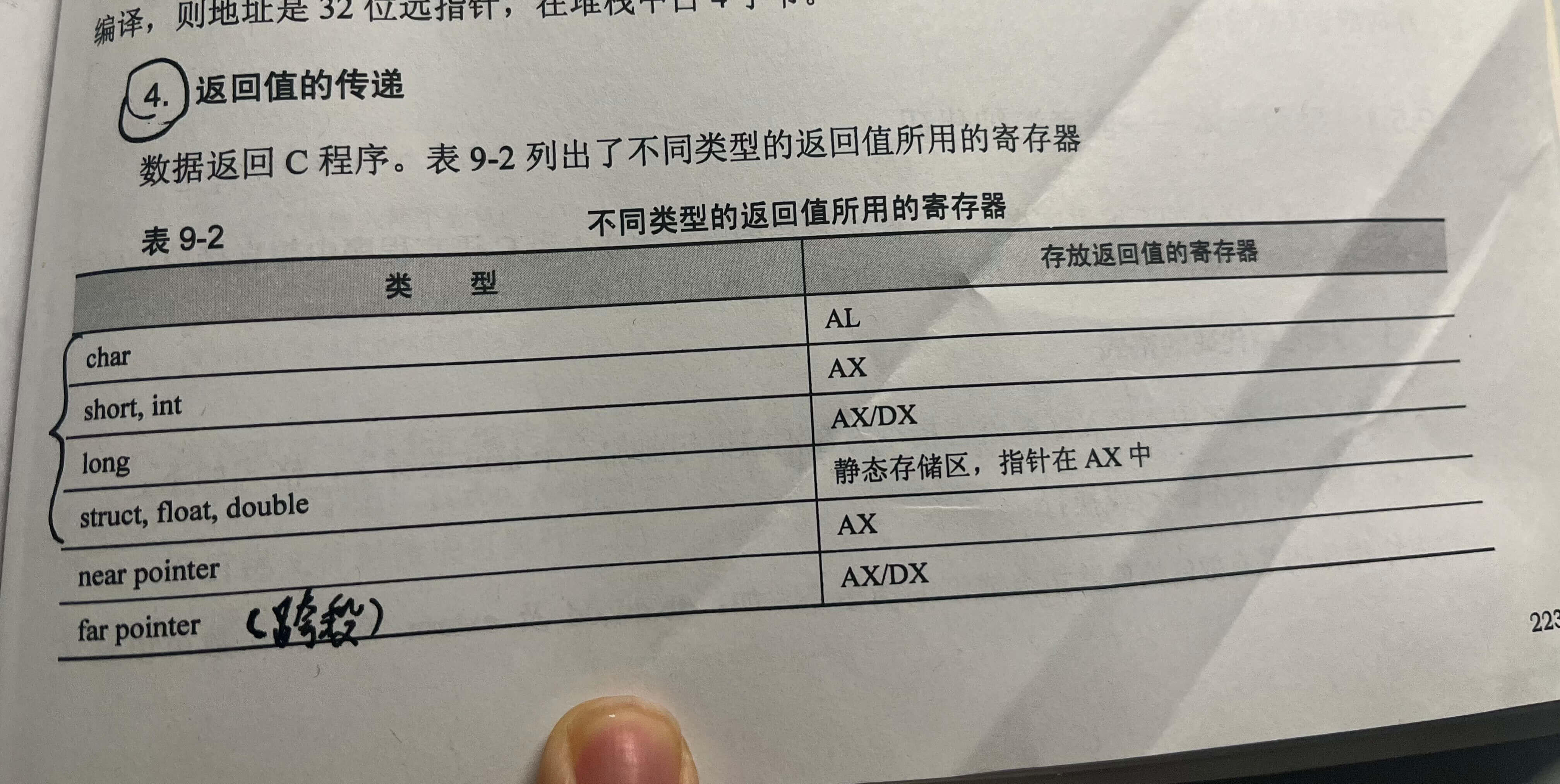
远近指针(Far Pointers and Near Pointers):
-
在早期的x86平台中,内存地址由段(Segment)和偏移量(Offset)组成。在这种情况下,指针可以分为远指针(Far Pointer)和近指针(Near Pointer)。
-
近指针指向当前段内的偏移量,通常只有16位,因此只能访问当前段的64KB内存。这种指针称为"近指针"。
-
远指针包含段和偏移量,可以跨越多个段,因此能够访问更多的内存空间。这种指针称为"远指针"。
但是,现代CPU已经没有远近指针的概念。 注意,这里64KB是一个很关键的词。
内存模型(Memory Model):内存模型是编译器和链接器所采用的一种抽象概念,用于描述程序在内存中的布局、组织、管理以及访问方式。它涉及了程序中的代码、数据、变量、函数、指针等在内存中的存储和访问方式。
具体而言,内存模型包括以下方面的内容:
-
内存布局:描述了程序在内存中的整体结构。这包括代码段、数据段、堆、栈等不同区域的划分和组织方式。
-
地址分配方式:描述了变量、函数、指针等在内存中分配地址的方式。这涉及到内存的分配策略、地址空间的划分等。
-
变量存储:描述了不同类型的变量在内存中的存储方式。例如,局部变量存储在栈上,全局变量和静态变量存储在数据段或BSS段中。
-
函数调用约定:描述了函数调用过程中参数的传递、返回值的获取以及寄存器的使用方式。不同的函数调用约定会影响到函数调用时栈的布局和寄存器的保存与恢复。
-
指针和内存访问:描述了指针变量在内存中的表示方式以及指针操作的规则。包括指针的大小、指针的引用和解引用等操作。
总的来说,内存模型提供了一种抽象的视角,使得编译器和链接器能够在编译和链接过程中有效地管理程序的内存使用,从而保证程序的正确性、可靠性和性能。
在现代操作系统中,通常采用的是平坦内存模型(Flat Memory Model)。在平坦内存模型下,整个内存空间被视为一个连续的、线性的地址空间,没有段的概念,因此不再需要使用远近指针的概念。
2. 指令装载
《微机原理与接口技术》p38
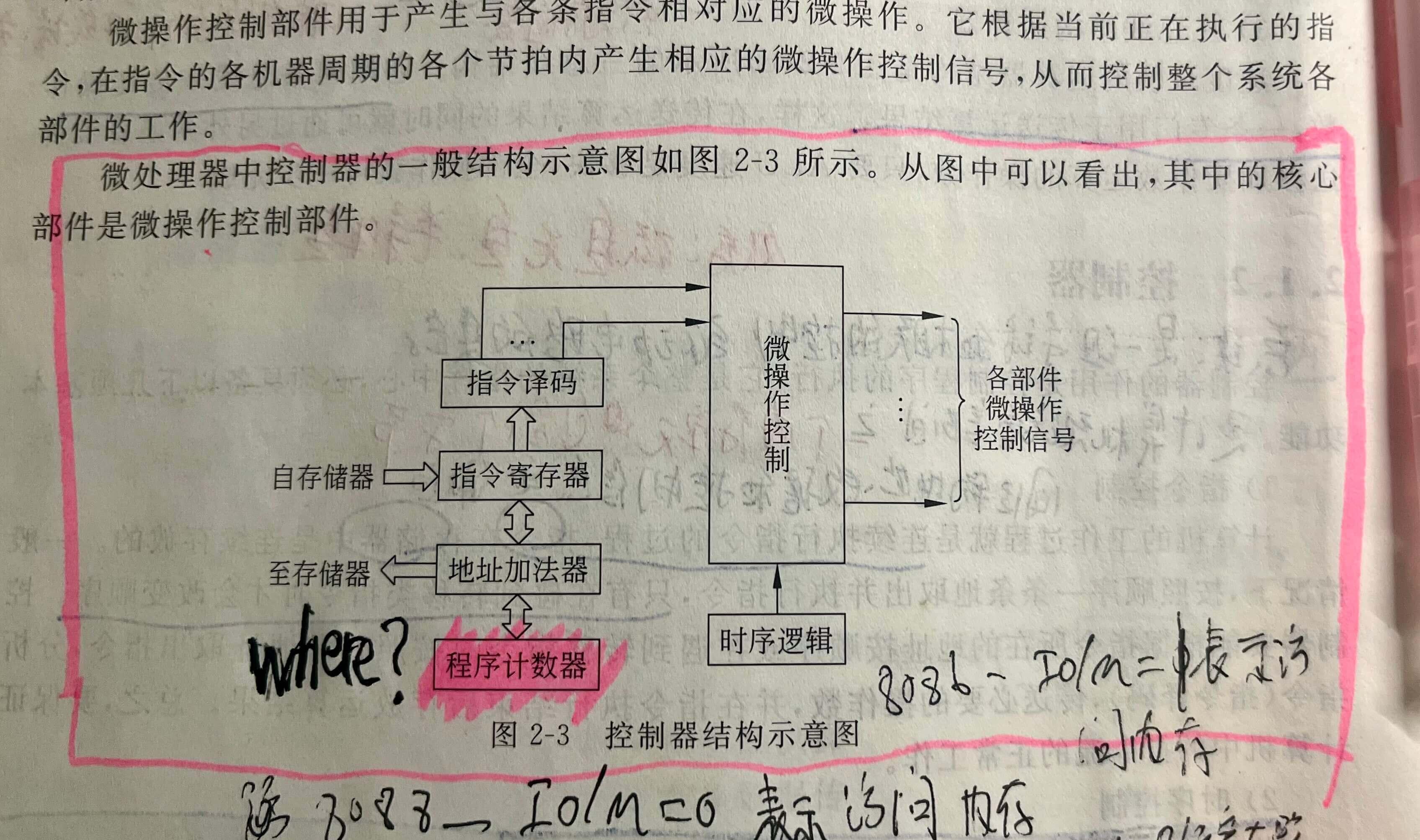
嗨嗨嗨!我们思考两个问题:
-
指令是如何加载的?
-
程序计数器在哪里?
8086CPU有说有pc 吗?没pc 怎么去执行指令呢?我超!是不是突然悟了,具体怎么回事呢?
之前说A64(M1)下是有pc的,反正8086没有,总之最后两个CPU都可以执行指令,怎么实现的呢?
下面通过两个demo来感受下。
2.1 8086的pc在哪里
略
8086的pc是用 CS:IP 的组合来实现。
2.2 看看A64的pc在哪里
具体看视频操作。
2.3 pc与可恶的缓冲区溢出
我们知道,pc寄存器全称为Program Counter,pc寄存器在指令执行时起了至关重要的作用。该寄存器内存储的是即将执行的指令的地址,当CPU执行一个指令时,其首先会访问pc寄存器,将其存储的值看作下一条指令地址,从内存中获取相应的指令,进一步译码、执行。对于黑客来说,攻击一个程序,往往本质上都是控制程序的pc寄存器,使其值由自己控制,从而能够让程序执行攻击者想要执行的指令。
下面主要通过一个不太完善的小例子,来演示缓冲区溢出:
#include <stdio.h>
#include <string.h>
void vulnerable_function() {
char buffer[10];
gets(buffer); // 漏洞点,没有输入边界检查,可能导致缓冲区溢出
}
void malicious_code() {
printf("Malicious code executed!\n");
}
int main() {
vulnerable_function();
printf("Normal execution resumed!\n");
return 0;
}
记得编译的时候,强制 -w 善意的警告此时不需要!
3. 地址🥹
p45《微机原理与接口技术》

前面有提到64KB这个很关键的数字,现在来解释。在解释之前,要再提一下上面说的,内存模型的概念。
:
-
平坦内存模型(Flat Memory Model):在平坦内存模型下,整个程序的地址空间是连续的,可以直接寻址任意内存位置。这种模型常见于现代操作系统和大多数桌面应用程序的编译过程中,因为它可以提供简单而高效的内存管理。
-
分段内存模型(Segmented Memory Model):在分段内存模型下,程序的地址空间被划分成多个段(Segment),每个段有不同的大小和属性。程序通过段选择器和偏移量来访问内存,而不是直接使用线性地址。这种模型通常用于一些早期的操作系统和一些特殊的应用场景中。
**再提一嘴:**在现代操作系统中,通常采用的是平坦内存模型(Flat Memory Model)。在平坦内存模型下,整个内存空间被视为一个连续的、线性的地址空间,没有段的概念,因此不再需要使用远近指针的概念。
3.1 8086的地址是怎么一会事儿?
p21 《汇编语言》
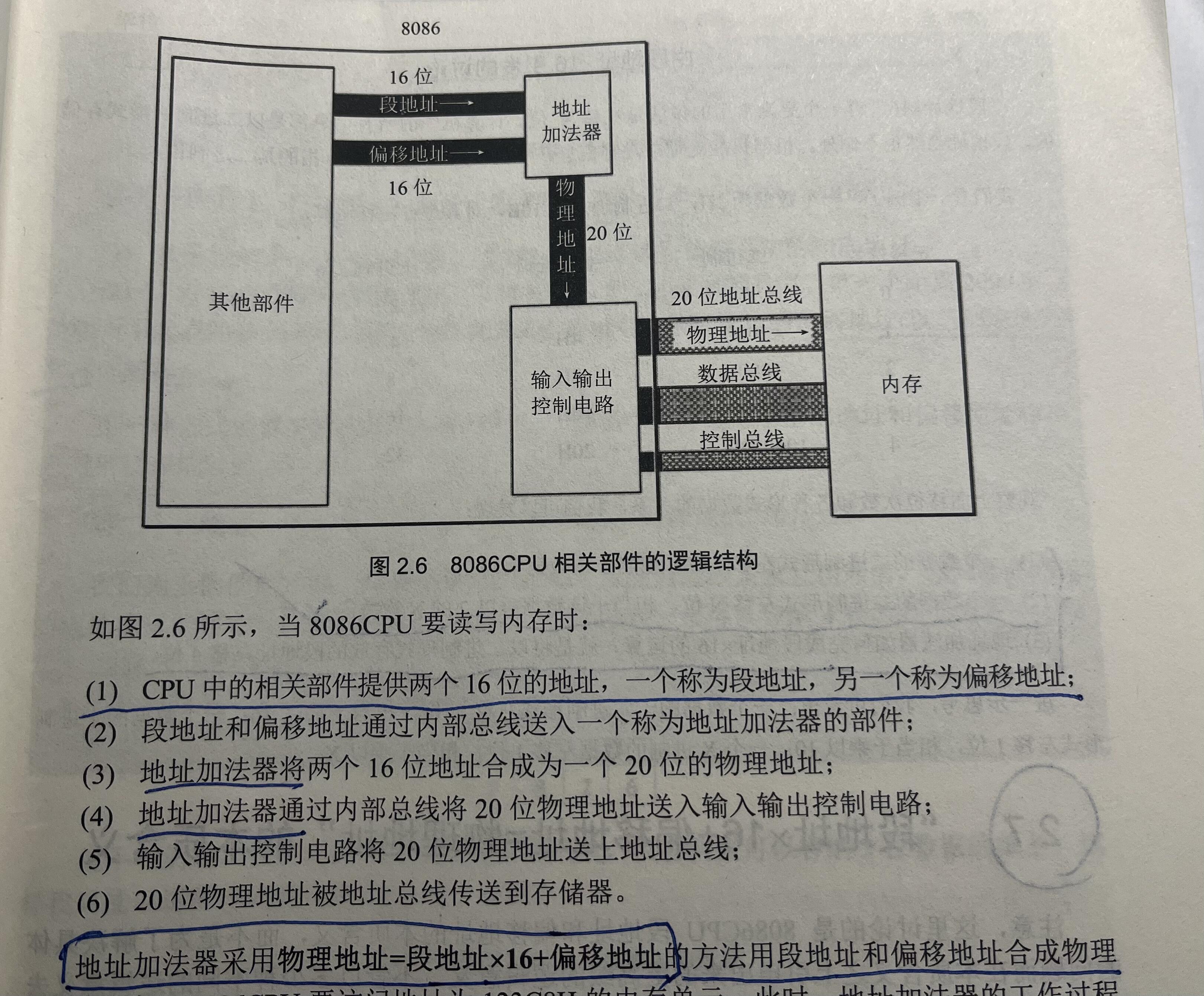
就是,这样就能“提升”寻址能力到1MB。这也是8086CPU很🐮的地方。
3.2 我爱demo
具体看视频,然后来感受下,地址的绝对性和相对性。
再提公式:物理地址=段地址*16+偏移地址
-r
//
-e 2000:1F60
//
-d 2000:1F60
-d 2100:0F60
-d 21F0:0060
// DS
-r DS
2000
-a
CS:IP mov ax,[60]
-t
-r
CS:IP mov bx,[64]
参考书籍
-
《微机原理与接口技术》 ISBN:9787302446453
-
《C指针编程之道》 ISBN:9787155250841
-
《汇编语言》 ISBN:9787302539414
更新于:2020年12月27日